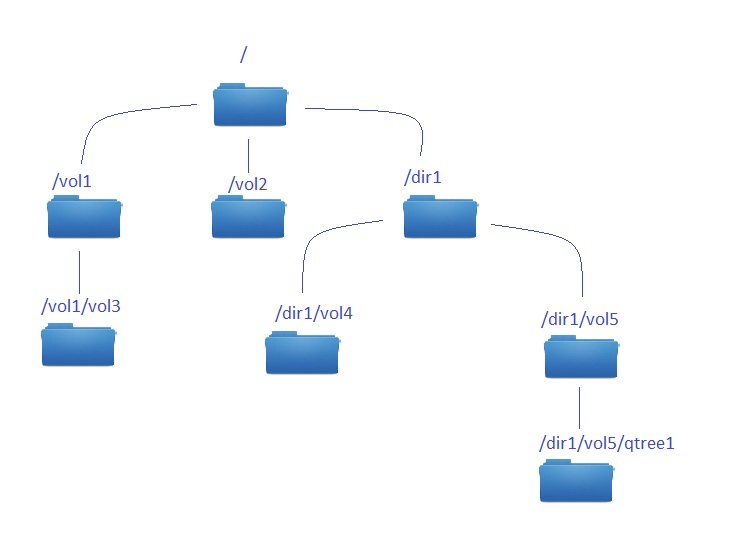
This entry is a follow-up of an example from my previous post about junction paths and namespaces (entire post you can find here: NetApp cDOT – Namespace, junction path). Today I would like to show you from ‘technical’ point of view how easy it is to modify junction paths for your volumes.
Let me first bring the example:
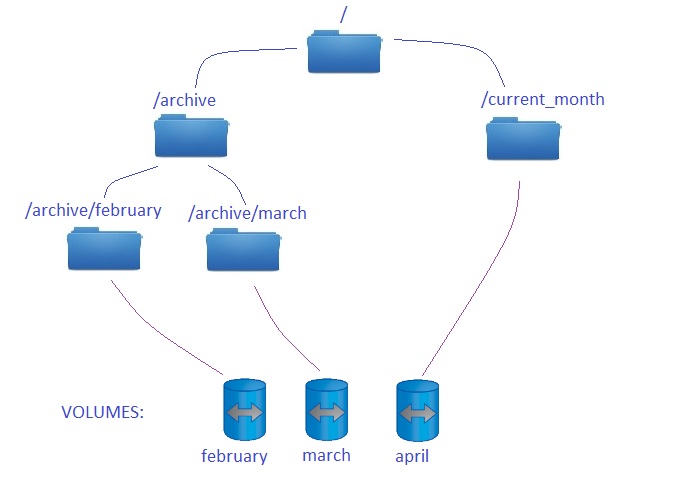
Namespace example – step 1
In my example path /current_month is used to store documents and reports from the running month. When the month is over we still want to have an access to those reports in /archive/<month_name> location. Step one can be seen form clustershell as:
cDOT01::> vol show -vserver svm1 -fields junction-path (volume show) vserver volume junction-path ------- ------ -------------- svm1 april /current_month svm1 february /archive/february svm1 march /archive/march svm1 svm1_root / 4 entries were displayed.
Let’s assume april is about to finish and we have to get ready for next month. Using feature of junction paths you do not have to physically move any data, and the whole operation can be done with just couple of commands.
Step 1: First you have to unmount april from /current_month:
cDOT01::> volume unmount -vserver svm1 april cDOT01::> vol show -vserver svm1 -fields junction-path (volume show) vserver volume junction-path ------- ------ ------------- svm1 april - svm1 february /archive/february svm1 march /archive/march svm1 svm1_root / 4 entries were displayed.
Caution: Since volume april is not mounted now – it cannot be accessed via NAS protocols / your customers.
Step 2: Mount april to the correct junction-path:
cDOT01::> volume mount -vserver svm1 -volume april -junction-path /archive/april cDOT01::> vol show -vserver svm1 -fields junction-path (volume show) vserver volume junction-path ------- ------ -------------- svm1 april /archive/april svm1 february /archive/february svm1 march /archive/march svm1 svm1_root / 4 entries were displayed.
Step 3. Create a new volume for your current reports:
cDOT01::> volume create -vserver svm1 -volume may -size 100m -aggregate aggr1 -junction-path /current_month [Job 34] Job succeeded: Successful
As you may noticed – you can mount the volume to the correct junction-path within volume mount command, or during volume create you can just specify your junction path with -junction-path parameter. Now, let’s check if our namespace is correct:
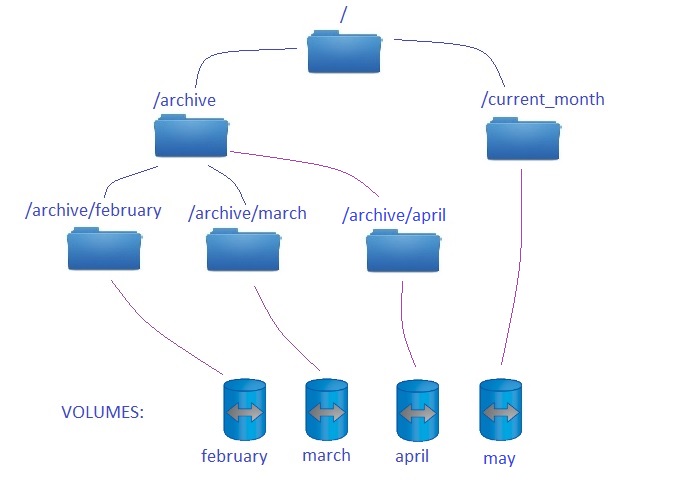
cDOT01::> vol show -vserver svm1 -fields junction-path (volume show) vserver volume junction-path ------- ------ -------------- svm1 april /archive/april svm1 february /archive/february svm1 march /archive/march svm1 may /current_month svm1 svm1_root / 5 entries were displayed.
And it is – exactly as on below example:
Namespace example – result