In today’s digital era, businesses across the globe are inundated with vast oceans of unstructured data. From emails and documents to social media posts and beyond, this data holds invaluable insights that can drive innovation, enhance customer satisfaction, and streamline operations. However, the sheer volume and complexity of unstructured data present significant challenges in terms of analysis and information retrieval. Traditional data processing tools often fall short when faced with the nuanced, irregular, and often unpredictable nature of this data.
Enter Google Gemini 1.0 Pro, a cutting-edge Generative AI Model. In this article I would like to propose an intriguing way of utilizing such models to navigate the labyrinth of unstructured data with unprecedented ease and efficiency. By leveraging the power of Gemini 1.0 Pro, businesses can transform their data analysis processes, uncovering the hidden gems of information that lie buried within the digital textual chaos.
The First Challenge: Diverse Data Formats
One of the most common hurdles in data analysis is the wide variation in how information can be presented, particularly with dates. Dates are pivotal in data analysis, serving as crucial markers for events, deadlines, transactions, and historical records. However, the flexibility with which dates can be written poses a significant challenge for standardization and subsequent analysis. For example, consider the following sentence, laden with dates expressed in varied formats:
“In our last meeting on Feb 15th, 2023, we discussed the project deadline initially set for 15/02/2023, which was later postponed to March 20th of the same year.”
The three dates written down in this examples are easy for us, humans, to understand, but if we would like to automatically retrieve them in structured way, we need to be able to present them in same format. Let’s assume our format is YYYY-MM-DD.
To solve that with Gemini, let’s navigate to Vertex AI Studio -> Language and create a new Text Prompt. Next step is to draft a proper Prompt explaining model what we are trying to achieve. In this case we can try with:
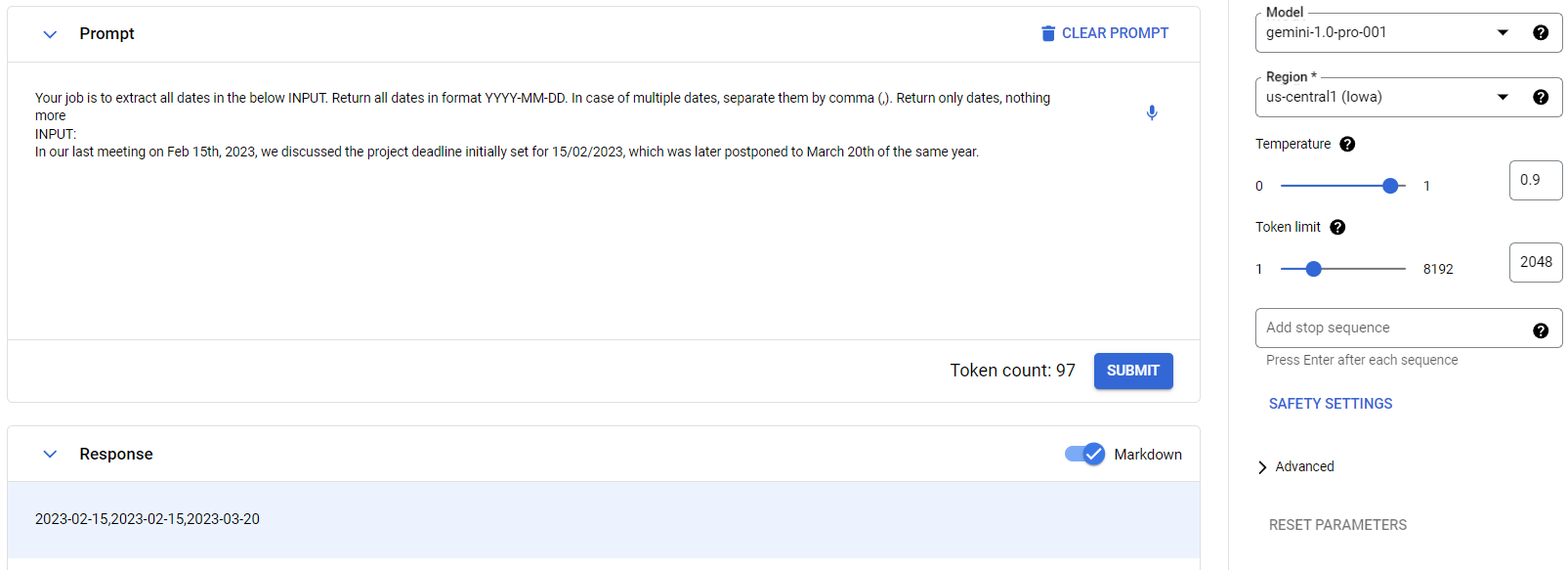
Gemini 1.0 Prompt to extract dates
With example prompt:
In our last meeting on Feb 15th, 2023, we discussed the project deadline initially set for 15/02/2023, which was later postponed to March 20th of the same year.
We got the expected result:
2023-02-15,2023-02-15,2023-03-20
It’s great to have that in Google Cloud Console. But what if we want to incorporate the solution in our program? I got you covered, taking advantage of ‘<> Get Code’ Functionality in Google Cloud, we can extract Python code for such application. I create this Colab notebook.
The Second Challenge: Automating Ticket Logging from User Emails
We had our fun with the first challenge, diving into the world of dates and their myriad formats. Now, let’s dial up the complexity and put Gemini to a real test. Imagine you’re part of a bustling help desk or service desk team. Your inbox is overflowing with user emails, each crying out for attention and begging to be logged as tickets in your system. The manual slog through this email avalanche is not just tedious; it’s a prime candidate for automation salvation.
Enter our next scenario: What if we could create a system that not only understands these emails but also acts on them, freeing you from the drudgery of manual logging? Picture this: An email lands in your inbox, detailing woes and pleas for help. Instead of the usual copy-paste routine, your new digital ally, powered by Gemini, steps in to parse, understand, and log the ticket for you.
Let’s take a look at an all-too-familiar plea for help as our example:
From: Emily Thompson emily.thompson@company.com
Subject: Printer Issue: Assistance Required
Email Content:
Hey IT Support Team,
I hope this message finds you well. I’m in a bit of a bind here with the printer—it’s just sitting there, stubbornly refusing to print. I’ve tried coaxing it, checking its connections, ensuring it’s powered on, but no luck. It’s like it’s decided to take a personal day!
Could you work your magic and get this thing back in action? I’ve got documents piling up that need seeing the light of day.
Thanks a bunch for jumping on this!
Cheers,
Emily
With this example, we’re dealing with unstructured data that’s packed with a whole bunch of information. From the sender’s name and email address to the specific issue they’re facing and the actions they’ve already taken to resolve it, there’s a wealth of details waiting to be uncovered. By extracting key pieces of information such as the user’s contact details, the nature of the problem, any troubleshooting steps already attempted, and the urgency of the request, we can harness this data to efficiently log a ticket in our ticketing system. This approach not only streamlines the process but also ensures that no critical information is overlooked in the hustle and bustle of help desk operations.
Like in the first example, we want to extract structured data, that can be further processed by some functions or methods. One of the nice structured way we can present our data is in JSON format, and I will go ahead with this example. The prompt could look like:
prompt = f'''
**Input Text:**
{issue}
**Instructions:**
Given the above input text, extract and organize the information into a structured JSON format. This information will be used to log a ticket, so propose a proper title and category that fits the reported issue. additional_info might include troubleshooting steps already executed, or any other useful information. The output should consist of the JSON structure only, without any additional characters or explanations.
**Output structure:**
{{
"name": "",
"email": "",
"title": "",
"category": "",
"short_summary": "",
"full_description": "",
"additional_info": ""
}}
'''Of course we can use this example in Vertex AI Studio, but since this is multiple-line input/output, please refer to this colab notebook, and I encourage you to try run the example yourself!
Running this prompt results in:
```json
{
"name": "Emily Thompson",
"email": "emily.thompson@company.com",
"title": "Printer Issue: Inaccessible",
"category": "Hardware",
"short_summary": "Printer not printing despite troubleshooting attempts",
"full_description": "The printer is unresponsive and not printing documents. Power is on, and connections are secure. User has attempted basic troubleshooting steps without success.",
"additional_info": "Troubleshooting steps executed:\n1. Checked connections\n2. Ensured power is on\n3. Restarted the printer"
}
```
And there we have it—a neatly structured, JSON-formatted dataset meticulously extracted from a user’s email. This transformation not only showcases the finesse with which unstructured data can be tamed but also underscores the practical utility of Generative AI in everyday problem-solving.
Summary
If you haven’t done it so already – check out the colab notebook created for this tutorial: colab notebook
In this tutorial, my primary focus has been on showcasing the powerful capabilities of Generative AI, particularly through the lens of Google Gemini 1.0 Pro, in extracting and structuring valuable information from the unstructured data inundating our digital workspaces. While the resulting JSON output, as illustrated above, offers a neatly organized structure ripe for further processing, the specifics of how this data might be integrated into a ticketing system or utilized in subsequent workflows is beyond the scope of this guide. There are myriad ways to leverage such structured data—ranging from automated ticket logging to advanced analytical processes—each tailored to the unique needs and infrastructures of different organizations. My aim here is to illuminate the path from chaos to clarity, turning the often overwhelming streams of unstructured data into actionable, structured insights. For those interested in the next steps—how to operationalize this data within your systems or applications—I encourage you to explore the myriad of possibilities that this structured data opens up, keeping in mind that the methods and tools you choose will be as diverse as the challenges and opportunities that your specific context presents.
Google Cloud credits are provided for this project. #GeminiSprint