When I was getting into NetApp I had a big trouble understanding the difference between snapvault and snapmirror. I heard an explanation: Snapvault is a backup solution where snapmirror is a DR solution. And all I could do was say ‘ooh, ok’ still not fully understanding the difference…
The first idea that poped out to my head was that snapmirror is mainly set on volume level, where snapvault is on qtree level. But that is not always the case, you can easily setup QSM (Qtree snapmirror).
The key to understanding the difference is really understand the sentence: Snapvault is a backup solution where snapmirror is a DR solution.
What does it mean that SnapVault is a backup solution?
Let me bring some picture to help me explain:
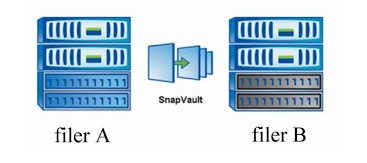
SnapVault
Example has few assumptions:
- we’ve got filerA in one location and filerB in other location
- that customer has a connection to both filerA and FilerB, although all shares to customers are available from filerA (via CIFS, NFS, iSCSI or FC)
- all customer data is being transfered to the filerB via Snapvault
What we can do with snapvault?
- as a backup solution, we can have a longer snapshot retention time on filerB, so more historic data will be available on filerB, if filerB has slower disks, this solution is smart, because slower disk = cheaper disks, and there is no need to use 15k rpm disk on filer that is not serving data to the customer.
- if customer has an network connection and access to shares on filerB he can by himself restore some data to filerA, even single files
- if there is a disaster within filerA and we loose all data we can restore the data from filerB
What we cannot do with snapvault?
- in case of an disaster within filerA we cannot “set” filerB as a production side. We cannot “revert the relationship” making the qtree on filerB as a source, and make them read/write. They are snapvault destinations so they are read-only.
- (having snapmirror license available on filerB we can convert Snapvault qtree to snapmirror qtree which solves that ‘issue’)
What does it mean that SnapMirror is a DR solution?
Again, let me bring the small picture to help me explain:
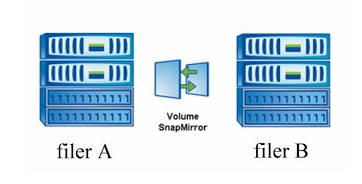
SnapMirror
Example has few assumptions:
- we’ve got filerA in one location and filerB in other location
- that customer has a connection to both filerA and FilerB, although all shares to customers are available from filerA
- all customer data is being transfered to the filerB via snapmirror
What we can do with snapmirror?
- as a backup solution we can restore the accidentally deleted, or lost data on filerA, if the snapmirror relationship has not been updated meantime
- if there is some kind or issue with filerA (from a network problem, to a total disaster) we can easily reverse the relationship. We can make the volume or qtree on filerB, as a source, and make it read-write, provide an network connection to the customer and voila – we are back online! After the issue has been solved we can resync the original source with changes made at the destination and reverse the relationship again.
To sum up
This is not the only difference between snapmirror and snpavault. But I would say this is the main one. Some other differences are that snapmirror can be actually in sync or semi-sync mode. The async mode can be updated even once a minute. Where the snapvault relationship cannot be updated more often then once an hour. If we have few qtrees on the same volume with SV they share the same schedule, while with QSM they can have different schedules, etc.. 😉
If you would like to know more check out this document: SnapVault Best Practices Guide
Data Protection Online Backup and Recovery Guide