Today I would like to brefily explain terms: export policy and export rule. In Netapp 7-mode if you wanted to create an NFS export you could add an entry to /etc/exports file and export it with exportfs command. In NetApp cDOT it is a different proceedure. To export an share via NFS you have to create an export-policy and assign it to either a Volume or a Qtree that you wish to export.
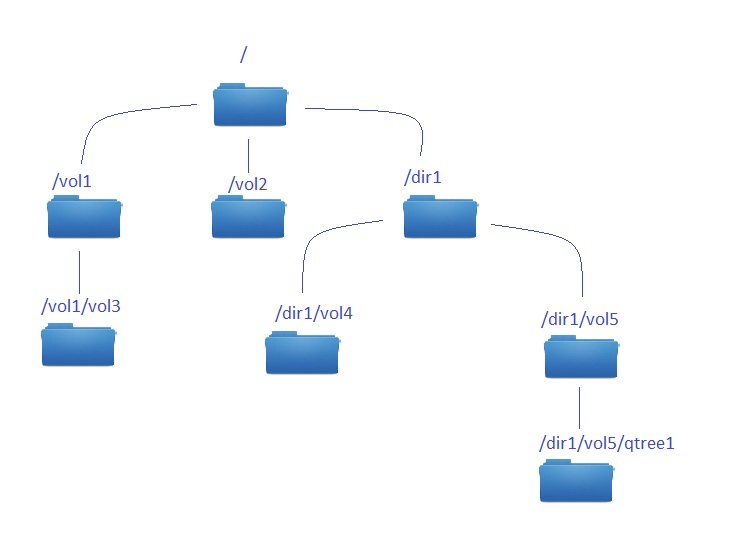
Another difference is the structure of NFS permissions. in 7-mode if you would like to access via NFS /vol/my_volume/my_qtree, you could just created an exportfs entry for that particular location. In Clustered Data ONTAP NFS clients that have access to the qtree also require at least read-only access at the parent volume and at root level.
You can easily verify that with “export-policy check-access” CLI command, example:
Example 1)
cdot-cluster::> export-policy check-access -vserver svm1 -volume my_volume -qtree my_qtree -access-type read-write -protocol nfs3 -authentication-method sys -client-ip 10.132.0.2 Policy Policy Rule Path Policy Owner Owner Type Index Access ----------------------------- ---------- --------- ---------- ------ ---------- / root_policy svm1_root volume 1 read /vol root_policy svm1_root volume 1 read /vol/my_volume my_volume_policy my_volume volume 2 read /vol/my_volume/my_qtree my_qtree_policy my_qtree qtree 1 read-write 4 entries were displayed.
In above example, host 10.132.0.2 has an read-access defined in root_policy and my_volume_policy exports policies. This host has also read-write access defined in rules of my_qtree_policy export policy.
Example 2)
cdot-cluster::> export-policy check-access -vserver svm1 -volume my_volume -qtree my_qtree -access-type read-write -protocol nfs3 -authentication-method sys -client-ip 10.132.0.3 Policy Policy Rule Path Policy Owner Owner Type Index Access ----------------------------- ---------- --------- ---------- ------ ---------- / root_policy svm1_root volume 1 read /vol root_policy svm1_root volume 1 read /vol/my_volume my_volume_policy my_volume volume 0 denied 3 entries were displayed.
In second example host 10.132.0.3 has an read-access defined in root_policy, however it does not have an read-access defined in volume’s policy my_volume_policy. Because of that this host cannot access /vol/my_volume/my_qtree even if it has read-write access in my_qtree_policy export policy.
Export policy
Export policy contain one or more export rule that process each client access request. Each Volume and qtree can have only one export policy assigned, however one export policy might be assigned to many volumes and qtrees. What is important – you cannot assign an export policy to a directory, only to objects like volumes and qtrees. As a consequence you cannot export via NFS a directory – in opposite to NetApp 7-mode, where it was possible (this article is written when the newest ONTAP version is 9.1).
Export rule
Each rule has an position, and that is the order in which client access is checked. It means that if you have an export rule (1) saying that 0.0.0.0/0 (all clients) have read-only access, and the rule (2) saying that LinuxRW host has an RW access, LinuxRW in fact will not get a RW permission, because during client access check, this host was already cought by rule 1, which only gave a RO access. Of course order of rules can be easily modified, it is important to pay attention to it.