In my last post I have explained a little bit Journal and Repository Volumes. If you know what those volumes as used for, you are aware that Journal Volumes hold poin-in-time history of the data. And in this short entry I would go a little bit into those point-in-time history.
Snapshot – as you can image, it’s a point-in-time snap, marked by the RecoverPoint system for recovery purposes. Within the EMC RecoverPoint a snapshot include only the data that has changed from the previous snapshot. The first Snapshot has all the changes between the moment of snapshot creation and
- current state – if only one snapshot is created
- next snapshot – if more snapshots are created
In other words – a snapshot is the difference between one consistent image of storage data and the next. In synchronous replication every write is a single snapshot. In asynchronous replication the RPA gathers several writes into a single snapshot (you can actually adjust that within the configuration.
Now, let’s get back for a second to EMC RecoverPoint – Introduction. As you know, the replication can be local or remote (or both!). Now, each Replica has its own Journal, so if you have same customer data replicated both locally and remote, you can have different policies for those two! For example synchronous replication for local protection and async replication for remote one.
Bookmark – a bookmark is a text label that is applied to a snapshot. In other way if you wish to manually create a snapshot and name it – boom, that’s it – you have a bookmark. You can create those if you need to have a specific point-in-time, e.g. right before the application upgrade, or right before the maintenance break etc.
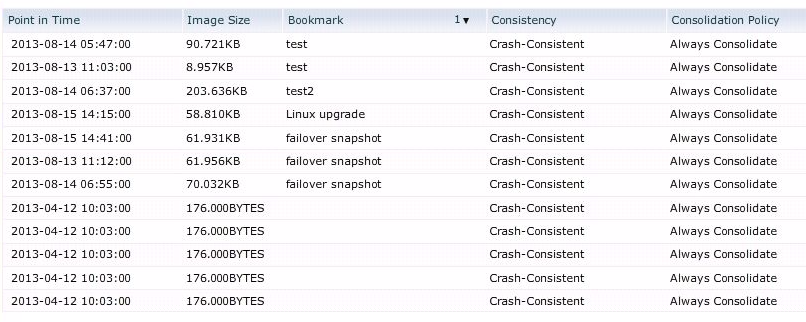
RecoverPoint Snapshots
As you can see on above print-screen, we have an example list of Snapshots, some of them have names, which makes them Bookmarks. Simple as that.


